Transformer Notes
Transformer Architecture
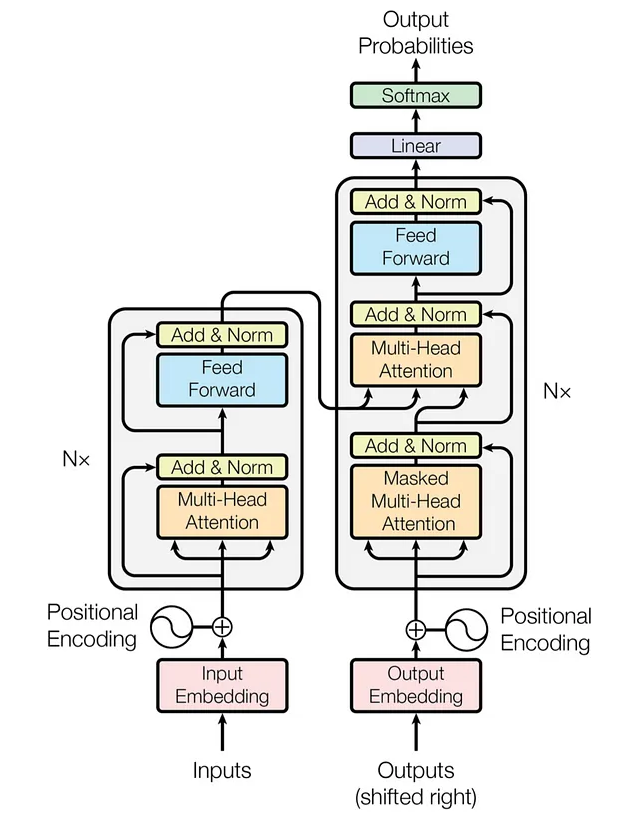
Key Definitions
-
Token index:
A token index is an integer that represents a specific token (word, subword or character) within a vocabulary.
-
Vocab Size:
This is the size of the vocabulary - the total number of unique tokens.
-
d_model:
The embedding dimension - the length of the vector that will represent each token.
-
Embedding Layer:
The embedding layer maps each token index to a $learned$ d_model dimensional vector. The embedding layer initializes a parameter matrix W of size [Vocab Size, d_model]. Each row of this matrix corresponds to the embedding vector for a particular token in the vocabulary.
-
Self-Attention:
A type of attention where the model relates different positions of a single sequence to compute a representation of that sequence.
-
Query (Q):
Vector representing what we're looking for in the attention computation.
-
Key (K):
Vector used to match against queries to determine attention weights.
-
Value (V):
Vector containing the actual content to be aggregated in attention computation.
-
Encoder:
Part of the transformer that processes the input sequence and creates a representation.
-
Decoder:
Part of the transformer that generates the output sequence based on the encoder's representation.
Transformer Fundamentals
-
Self-Attention Mechanism:
Core computation in transformers:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
where $Q$ is queries, $K$ is keys, $V$ is values, and $d_k$ is key dimension.
-
Multi-Head Attention:
- Parallel attention computations
- Each head captures different aspects of relationships
- Concatenated and projected to final output
Architecture Components
-
Encoder Block:
- Multi-head self-attention
- Feed-forward neural network
- Layer normalization
- Residual connections
-
Positional Encoding:
$$PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{model}})$$
Adds position information to token embeddings.
Training Techniques
-
Masked Training:
Used in decoder for autoregressive generation:
- Prevents attending to future tokens
- Essential for language modeling
-
Pre-training Objectives:
- Masked Language Modeling (MLM)
- Next Sentence Prediction (NSP)
- Causal Language Modeling
Model Variants
-
Popular Architectures:
- BERT: Bidirectional Encoder
- GPT: Autoregressive Decoder
- T5: Text-to-Text Transfer
- BART: Denoising Autoencoder
-
Specialized Variants:
- ViT: Vision Transformer
- DALL-E: Image Generation
- Perceiver: Universal Architecture
Advanced Concepts
-
Efficiency Improvements:
- Sparse Attention Patterns
- Linear Attention Mechanisms
- Parameter Sharing Techniques
-
Scaling Techniques:
- Model Parallelism
- Pipeline Parallelism
- Mixed Precision Training